
Vision
Deze inhoud is nog niet vertaald.
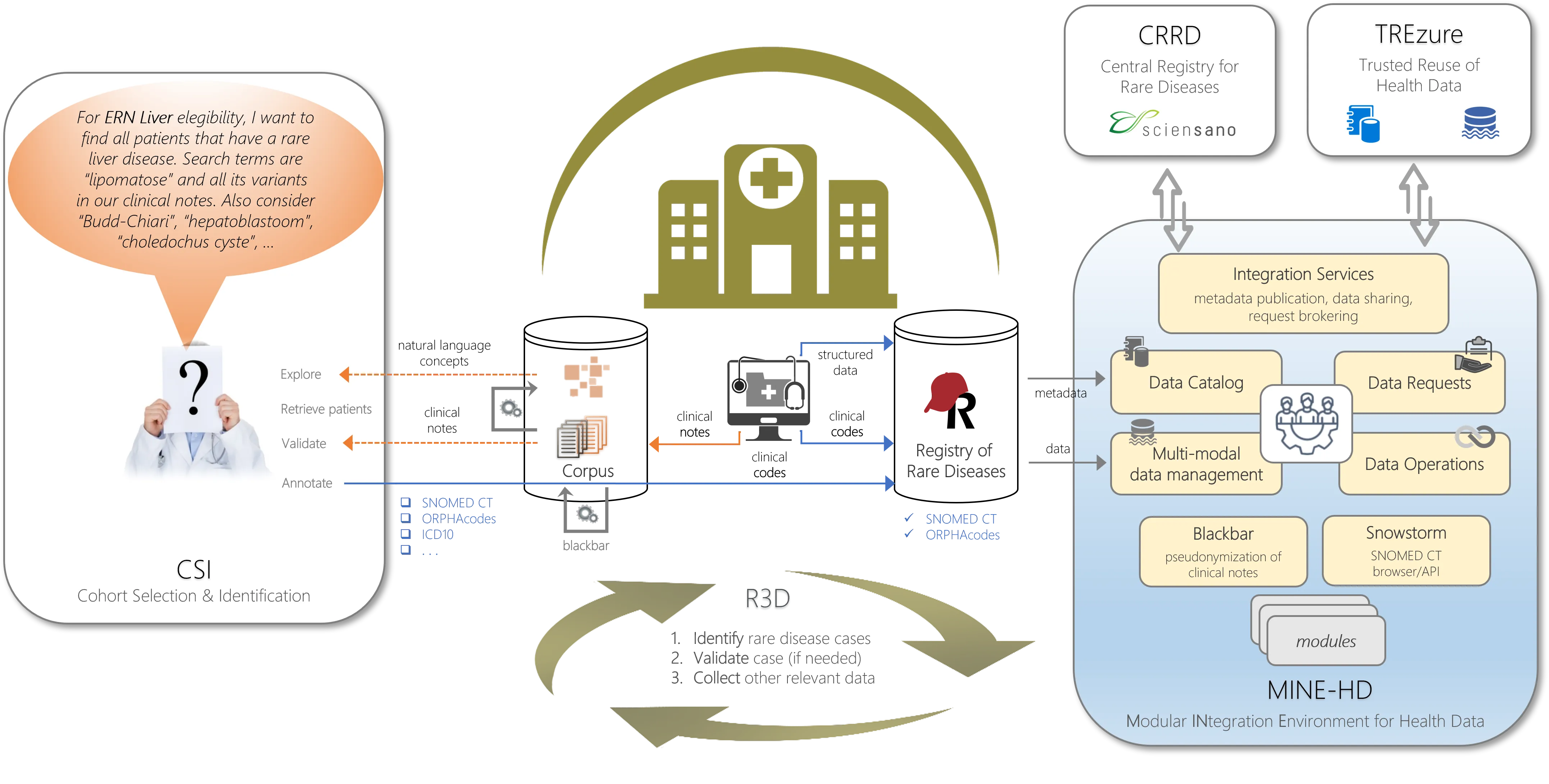
Organizations have come to realize the immense value that their data can create. They no longer view data as a mere byproduct of their processes and have started treating it as a strategic asset.
To maximize the utility of data, guiding principles have been established emphasizing its Findability, Accessibility, Interoperability, and Reusability. Collectively known as the FAIR data principles (https://www.go-fair.org/fair-principles), these serve as a framework to ensure data is well-organized, usable, and capable of driving value across various domains.
Health and healthcare data are a special category that has the potential to benefit not only individual patients but entire groups of patients and the broader healthcare system. Drawn from a wide range of complex medical cases, this data can provide valuable insights that fuel advancements in medical research, enhance public health outcomes, and inform evidence-based health and policy decisions. When leveraged responsibly, hospitals can use this wealth of data to develop new treatments, improve quality of life, identify emerging health trends, and make the healthcare delivery system more efficient.
However, healthcare providers struggle to make patient data available to internal and external stakeholders in a safe and consistent way. SPECTRE-HD wants to help overcome some of the major challenges and unlock the full potential of healthcare data.
Challenges
Section titled “Challenges”Fragmented Data Ecosystems
Section titled “Fragmented Data Ecosystems”Healthcare data is often siloed across multiple systems, such as EHRs, imaging platforms, and laboratory databases, complicating its integration and reuse.
Legacy systems and databases may lack interoperability with modern tools, making it harder to provide scalable and consistent data-sharing capabilities.
Lack of Standardization
Section titled “Lack of Standardization”Data reuse is complicated by variability in data formats, terminologies, and metadata. Hospitals use different EHR systems and do not consistently follow standards like SNOMED CT or OMOP-CDM, leading to misaligned data across hospitals.
Multimodal data
Section titled “Multimodal data”Not all healthcare data fits nicely into rows and columns that are easily stored in relational databases. A lot of data is unstructured and does not have a predefined format, like text, images, videos, and other multimedia content. Although structured data is easier to handle and analyze, unstructured data often contains richer, more complex information that — when analyzed correctly — can provide deeper insights. Analyzing both structured and unstructed data requires advanced tools to store, integrate, process and interpret for valuable insights.
Privacy and Compliance Concerns
Section titled “Privacy and Compliance Concerns”Stringent data protection regulations like GDPR make it challenging to process and share data securely, especially with external parties. Fear of privacy breaches or non-compliance - often due to inadequate pseudonymization capabilities - leads to underutilization of valuable datasets.
Technical Resource Constraints
Section titled “Technical Resource Constraints”IT staff in hospitals operate with limited personnel and budgets, making it difficult to address both day-to-day operations and strategic initiatives like data modeling and quality improvement. Handling numerous ad hoc requests leaves little bandwidth for proactive data governance or process automation.
Complexity of Stakeholder Needs
Section titled “Complexity of Stakeholder Needs”Different stakeholders (clinicians, researchers, administrators) often have varying and conflicting requirements for data access, formats, and delivery timelines. This creates significant pressure on the data team to meet expectations while maintaining compliance and data quality. Without a clear prioritization framework, the data team can struggle to balance competing demands.
Inefficient Request Management
Section titled “Inefficient Request Management”Data requests typically come through multiple, unstructured channels, such as emails or informal conversations, leading to delays, duplicated effort, and increased risk of miscommunication. Without a centralized and streamlined system, the data team struggles to track and prioritize requests effectively.
Insufficient Focus on Data Quality and Modeling
Section titled “Insufficient Focus on Data Quality and Modeling”Due to high workloads and the pressure to meet immediate requests, data teams may deprioritize critical tasks like data modeling, data cleansing, data validation, and schema standardization. This results in datasets that are difficult to reuse. Poor data quality undermines the potential for reuse, as stakeholders cannot fully trust or rely on the data.
Technological Gaps
Section titled “Technological Gaps”Many hospitals lack modern tools needed to create and automate ETL workflows, enhance metadata management, and ensure scalable data operations.
Advanced features like data lineage tracking, pseudonymization, and self-service analytics are often missing in legacy systems.
Cultural Barriers
Section titled “Cultural Barriers”Resistance to change among staff or leadership can slow the adoption of data-driven practices.
A lack of data literacy across stakeholders can lead to underutilization of available data assets.
Governance and Ownership Ambiguities
Section titled “Governance and Ownership Ambiguities”Unclear roles and responsibilities can result in inconsistent policies for data access and reuse.
Without a designated steward or clear accountability, datasets can become outdated or mismanaged.
The Role of a Modern Data Platform
Section titled “The Role of a Modern Data Platform”To address these challenges, the solutions and data platforms in SPECTRE-HD support many steps from data request to delivery, enabling hospitals to securely and efficiently manage their healthcare data.
The platform’s features include:
Centralized Data Request Management
Section titled “Centralized Data Request Management”- A streamlined interface where stakeholders can submit and track requests, ensuring transparency and reducing miscommunication.
- Automation of request workflows, including metadata validation and lineage tracking, to reduce manual errors.
Privacy and Security by Design
Section titled “Privacy and Security by Design”- Advanced pseudonymization and anonymization techniques to ensure compliance with GDPR and other regulations.
- Fine-grained access controls to restrict visibility of sensitive data, ensuring only authorized users can access or share specific datasets.
Robust Data Governance
Section titled “Robust Data Governance”- Tools to define roles and responsibilities, ensuring accountability for data stewardship.
- Integration with data and metadata standards like OMOP-CDM and DCAT-AP for Health to harmonize data across systems and improve reusability.
Scalable Data Operations
Section titled “Scalable Data Operations”- Integration with advanced technologies to handle large datasets and complex queries.
- Support for CI/CD workflows to automate testing, deployment, and validation of data pipelines.
Enhanced Data Quality and Modeling
Section titled “Enhanced Data Quality and Modeling”- Automated data validation processes to ensure datasets meet predefined quality standards.
- Comprehensive metadata management to document schemas, relationships, and lineage, improving transparency and usability.
Efficient Resource Utilization
Section titled “Efficient Resource Utilization”- Automation reduces the workload on scarce IT staff, allowing them to focus on higher-value tasks like strategic planning and infrastructure optimization.
- A modular and interface-based design ensures the platform can scale as demands increase, particularly with the introduction of EHDS initiatives.
Evolutions in Data Technology
Section titled “Evolutions in Data Technology”Over the past 25 years, the data technology landscape has changed significantly.
-
Early 2000s: Traditional Data Management and Warehousing
- Relational Databases Dominate: Most organizations relied on structured databases (e.g., Oracle, MySQL) and large-scale data warehouses (e.g., Teradata).
- Business Intelligence (BI): Tools like SAP BusinessObjects and IBM Cognos evolved, focusing on reporting and dashboards.
- Data Mining and Analytics: Basic machine learning and data mining techniques (e.g., decision trees, clustering) gained traction in fields like CRM and fraud detection.
-
Mid-to-Late 2000s: The Rise of “Big Data”
- Hadoop Ecosystem: Technologies like Hadoop and MapReduce emerged, enabling the storage and processing of massive datasets on commodity hardware.
- NoSQL Databases: Solutions like MongoDB, Cassandra, and CouchDB became popular for unstructured data use cases, breaking away from the rigid schemas of relational databases.
- Cloud Emergence: Amazon Web Services (AWS) led the charge in providing scalable, on-demand infrastructure, making large-scale data processing more affordable.
-
Early 2010s: Data Lakes and the Maturing of Big Data
- Streaming and Real-Time Analytics: Frameworks such as Apache Spark, Apache Kafka, and Storm allowed near real-time data processing and analytics at scale.
- Data Lakes: The concept of storing raw, unstructured data for later processing became mainstream. Organizations began shifting from traditional data warehouses to more flexible lake architectures.
- Machine Learning Renaissance: Improved algorithms, large datasets, and more computing power (especially via GPUs) drove breakthroughs in computer vision, speech recognition, and natural language processing.
-
Around 2020: Big Data Hype and Democratization of AI
- Mainstream Adoption: Enterprises across sectors embraced big data analytics, fueling demand for data science talent and “citizen data science” tools.
- Cloud-First Strategies: With Microsoft Azure and Google Cloud catching up to AWS, businesses grew comfortable outsourcing not just storage and compute, but also machine learning pipelines.
- Deep Learning Frameworks: TensorFlow, PyTorch, and scikit-learn matured, lowering barriers to entry for complex AI projects.
-
2021–2023: Foundation Models and Early Generative AI
- Transformers and Large Language Models (LLMs): Models such as GPT-3 and BERT showcased significant leaps in language understanding, proving useful in chatbots, coding assistants, and content generation.
- AutoML and MLOps: Automation of model training, hyperparameter tuning, and deployment processes became standard, encouraging more rapid experimentation and delivery of AI solutions.
- Ethical and Regulatory Focus: Issues around data privacy, bias, and responsible AI took center stage, prompting guidelines and legislation around AI governance and transparency.
-
2024-today: Explosion of Generative AI
- Generative AI Goes Mainstream: Next-generation LLMs and diffusion models dramatically improved text, image, and even video generation, capturing public imagination.
- Industry Integration: Generative AI capabilities embedded into consumer applications, healthcare diagnostics, drug discovery, and software development tools became widespread.
- Scaling and Specialization: Specialized “expert” models for industries like finance, legal, and healthcare provided domain-specific generative capabilities, driving further adoption.
- Continued Focus on Responsible AI: As generative models became more ubiquitous, discussions around data provenance, security, and regulatory frameworks intensified.
Overall, the journey from traditional data warehouses to generative AI exemplifies a continuous push to store, process, analyze, and leverage ever-growing volumes of data more effectively. Each milestone—whether Hadoop-based big data platforms or transformer-based language models—has served to expand both the technical toolkit and the practical applications of data technologies, culminating in a new era where AI not only processes information but creates content in ways previously unimaginable.
Mission
Section titled “Mission”It is clear that hospitals face significant challenges when it comes to securely and scalably processing and sharing sensitive patient information for reuse, both internally and with external parties. The complex, dispersed and unstructured nature of healthcare data combined with strict privacy regulations and diverse stakeholder needs, makes it difficult to meet growing demands. Without the right mix of processes, technology, and skilled staff, sharing data is a complex and time-consuming activity for all parties involved.
SPECTRE-HD wants to address these challenges by creating an ecosystem for hospitals to maximize the value of their healthcare data. It creates a secure, scalable foundation for data reuse that benefits all stakeholders, from clinicians and researchers to policymakers and public health organizations. Key outcomes include:
- Faster and more reliable data sharing across internal and external entities.
- Stronger trust among patients, caregivers, and regulators through improved data security and governance.
- Enhanced ability to support cutting-edge research and policy initiatives, including those aligned with the EHDS.
- This platform is not just a tool but a strategic enabler, helping hospitals overcome current challenges while preparing for a data-driven future.